Dataflow¶
In this chapter, we will introduce the dataflow and data format convention between the internal modules managed by the Runner.
Overview of dataflow¶
The Runner is an “integrator” in MMEngine. It covers all aspects of the framework and shoulders the responsibility of organizing and scheduling nearly all modules, that means the dataflow between all modules also controlled by the Runner. As illustrated in the Runner document of MMEngine, the following diagram shows the basic dataflow.
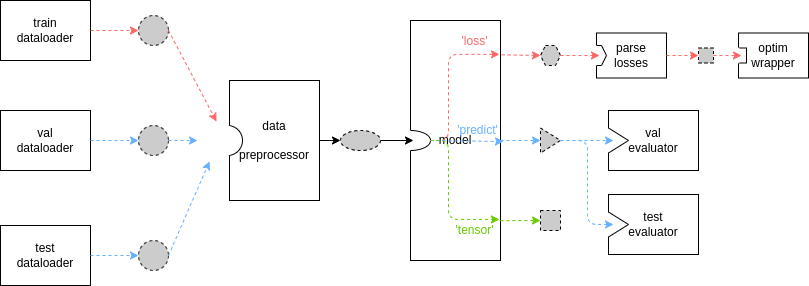
The dashed border, gray filled shapes represent different data formats, while solid boxes represent modules/methods. Due to the great flexibility and extensibility of MMEngine, some critical base classes can be inherited and their methods can be overridden. The diagram above only holds when users are not customizing TrainLoop, ValLoop, and TestLoop in Runner, and are not overriding train_step, val_step and test_step method in their custom model. The default setting of loops in MMSegmentation is as follows, it uses IterBasedTrainLoop to train models with 20000 iterations in total and do evaluation each 2000 iterations.
train_cfg = dict(type='IterBasedTrainLoop', max_iters=20000, val_interval=2000)
val_cfg = dict(type='ValLoop')
test_cfg = dict(type='TestLoop')
In the above diagram, the red line indicates the train_step. At each training iteration, dataloader loads images from storage and transfer to data preprocessor, data preprocessor would put images to the specific device and stack data to batch, then model accepts the batch data as inputs, finally the outputs of the model would be sent to optimizer. The blue line indicates val_step and test_step. The dataflow of these two process is similar to the train_step except the outputs of model, since model parameters are freezed when doing evaluation, the model output would be transferred to Evaluator to compute metrics.
Dataflow convention in MMSegmentation¶
From the diagram above, we could see the basic dataflow. In this section, we would introduce format convention of data involved in this dataflow, respectively.
DataLoader to Data Preprocessor¶
DataLoader is an essential component in training and testing pipelines of MMEngine. Conceptually, it is derived from and consistent with PyTorch. DataLoader loads data from filesystem and the original data passes through data preparation pipeline, then it would be sent to Data Preprocessor.
MMSegmentation defines the default data format at PackSegInputs, it’s the last component of train_pipeline and test_pipeline. Please refer to data transform documentation for more information about data transform pipeline.
Without any modifications, the return value of PackSegInputs is usually a dict and has only two keys, inputs and data_samples. The following pseudo-code shows the data types of the data loader output in mmseg, which is a batch of fetched data samples from the dataset, and data loader packs them into a dictionary of the list. inputs is the list of input tensors to the model and data_samples contains a list of input images’ meta information and corresponding ground truth.
dict(
inputs=List[torch.Tensor],
data_samples=List[SegDataSample]
)
Note: SegDataSample is a data structure interface of MMSegmentation, it is used as an interface between different components. SegDataSample implements the abstract data element mmengine.structures.BaseDataElement, please refer to the SegDataSample documentation and data element documentation in MMEngine for more information.
Data Preprocessor to Model¶
Though drawn separately in the diagram above, data_preprocessor is a part of the model and thus can be found in Model tutorial at data preprocessor chapter.
The return value of data preprocessor is a dictionary, containing inputs and data_samples, inputs is batched images, a 4D tensor, and some additional meta info used in data preprocesses would be added to the data_samples. When transferred to the network, the dictionary would be unpacked to two values. The following pseudo-codes show the return value of the data preprocessor and the input values of model.
dict(
inputs=torch.Tensor,
data_samples=List[SegDataSample]
)
class Network(BaseSegmentor):
def forward(self, inputs: torch.Tensor, data_samples: List[SegDataSample], mode: str):
pass
Note: Model forward has 3 kinds of mode, which is controlled by input argumentmode, please refer model tutorial for more details.
Model output¶
As model tutorial mentioned 3 kinds of mode forward with 3 kinds of output. train_stepand test_step(or val_step) correspond to 'loss' and 'predict' respectively.
In test_step or val_step, the inference results would be transferred to Evaluator. You might read the evaluation document for more information about Evaluator.
After inference, the BaseSegmentor in MMSegmentation would do a simple post process to pack inference results, the segmentation logits produced by the neural network, segmentation mask after the argmax operation and ground truth(if exists) would be packed into a similar SegDataSample instance. The return value of postprocess_result is a List of SegDataSample. Following diagram shows the key properties of these SegDataSample instances.

The same as Data Preprocessor, loss function is also a part of the model, it’s a property of decode head.
In MMSegmentation, the method loss_by_feat of decode_head is an unified interface used to compute loss.
Parameters:
seg_logits (Tensor): The output from decode head forward function.
batch_data_samples (List[:obj:
SegDataSample]): The seg data samples. It usually includes information such asmetainfoandgt_sem_seg.
Returns:
dict[str, Tensor]: a dictionary of loss components
Note: The train_step transfers the loss into OptimWrapper to update the weights in model, please refer train_step for more details.